Refactor the first learning notes followed with https://www.youtube.com/watch?v=P6sfmUTpUmc&t=3014s
// Install dependencies
#r "nuget:Plotly.NET.Interactive"
#r "nuget:TorchSharp,0.99.3"
#r "nuget:libtorch-cuda-11.7-win-x64,1.13.0.1"
#r "nuget:Microsoft.DotNet.Interactive.Formatting,*-*"
open System
open System.IO
open Plotly.NET
open TorchSharp
open type TorchSharp.torch.nn.functional
open Microsoft.DotNet.Interactive.Formatting
Formatter.SetPreferredMimeTypesFor(typeof<torch.Tensor>, "text/plain")
Formatter.Register<torch.Tensor>(fun (x:torch.Tensor) -> x.ToString(TorchSharp.TensorStringStyle.Default))
let print x = Formatter.ToDisplayString x |> printfn "%s"
let (@) (x: torch.Tensor) (y: torch.Tensor) = x.matmul y
let (^) x y = Math.Pow(x, y)
let scalar (x: float)= Scalar.op_Implicit x
let words = File.ReadAllLines "MakeMore.names.txt" |> Seq.sortBy (fun _ -> Random.Shared.Next()) |> Seq.toList
words |> Seq.take 5
let chars =
let set = System.Collections.Generic.HashSet()
words |> Seq.iter (fun word -> word |> Seq.iter (set.Add >> ignore))
set |> Seq.sort |> Seq.toList
let lookupTable =
Map.ofList [
'.', 0
for i, c in List.indexed chars do c, i + 1
]
let size = lookupTable.Count
let ctoi c = Map.find c lookupTable
let itoc i = lookupTable |> Map.pick (fun k x -> if x = i then Some k else None)
let n_embed = 10 // the dimensionality of the character embedding vectors
let n_hidden = 100 // the number of neurons in the hidden layer of the MLP
let block_size = 8
let g = torch.Generator().manual_seed(2122123) // for reproducibility
let X, Y =
[|
for word in words do
let iend = size - 1
let mutable context = [for _ in 1..block_size -> 0]
for c in word do
let ix = ctoi c
List.toArray context, ix
context <- List.append context[1..] [ix]
List.toArray context, 0
|]
|> Array.unzip
|> fun (x, y) ->
torch.tensor(array2D x),
torch.tensor(y)
// Check the input and label pair
torch.cat(
System.Collections.Generic.List [
X[[|0L..20L|]]
Y[[|0L..20L|]].view(-1, 1)
],
1
).data()
|> Seq.chunkBySize (block_size + 1)
|> Seq.iter (fun row ->
printfn "%s => %s" (row[..block_size-1] |> Seq.map itoc |> String.Concat) (itoc row[block_size] |> string)
)
// ........ => m
// .......m => a
// ......ma => t
// .....mat => h
// ....math => i
// ...mathi => l
// ..mathil => d
// .mathild => a
// mathilda => .
// ........ => s
// .......s => a
// ......sa => m
// .....sam => a
// ....sama => n
// ...saman => t
// ..samant => h
// .samanth => a
// samantha => .
// ........ => o
// .......o => m
// ......om => .
// Training split, test split
// 90% 10%
let total = words.Length
let trainCount = float total * 0.9 |> int
let testCount = float total * 0.1 |> int
let X_train = X[torch.arange(trainCount)]
let Y_train = Y[torch.arange(trainCount)]
let X_test = X[torch.arange(trainCount, trainCount + testCount)]
let Y_test = Y[torch.arange(trainCount, trainCount + testCount)]
type ILayer =
abstract member Forward: x: torch.Tensor -> torch.Tensor
abstract member Parameters: torch.Tensor list
abstract member Out: torch.Tensor
type Linear(fanIn: int, fanOut: int, generator: torch.Generator, ?withBias) =
let mutable out = Unchecked.defaultof<torch.Tensor>
let mutable weight = torch.randn(fanIn, fanOut, generator = generator) / scalar(fanIn ^ 0.5)
let bias = if defaultArg withBias true then Some(torch.zeros(fanOut)) else None
member _.UpdateWeight(fn) = weight <- fn weight
interface ILayer with
member _.Forward(x) =
out <- x @ weight
out <-
match bias with
| None -> out
| Some bias -> out + bias
out
member _.Parameters =[
weight
match bias with
| None -> ()
| Some bias -> bias
]
member _.Out = out
type BatchNorm1d(dim: int, ?eps, ?momentum) as this =
let mutable out = Unchecked.defaultof<torch.Tensor>
let eps = defaultArg eps 1e-5 |> scalar
let momentum = defaultArg momentum 0.1 // 动量,推进力
let mutable gamma = torch.ones(dim)
let beta = torch.zeros(dim)
let mutable running_mean = torch.zeros(dim)
let mutable running_var = torch.ones(dim)
member val IsTraining = true with get, set
member _.UpdateGamma(fn) = gamma <- fn gamma
member _.RuningVar = running_var
member _.RuningMean = running_mean
member _.Gamma = gamma
member _.Beta = beta
interface ILayer with
member _.Forward(x: torch.Tensor) =
let xmean = // 平均值
if this.IsTraining then x.mean([| 0 |], keepdim = true)
else running_mean
let xvar = // 方差 https://pytorch.org/docs/stable/generated/torch.var.html?highlight=var#torch.var 数的离散程度
if this.IsTraining then x.var(0, keepdim = true, unbiased = true)
else running_var
let xhat = (x - xmean) / (xvar + eps).sqrt() // Normalize to unit variance
out <- xhat * gamma + beta
if this.IsTraining then
use _ = torch.no_grad()
running_mean <- scalar(1. - momentum) * running_mean + scalar(momentum) * xmean
running_var <- scalar(1. - momentum) * running_var + scalar(momentum) * xvar
out
member _.Parameters = [ gamma; beta ]
member _.Out = out
type Tanh() =
let mutable out = Unchecked.defaultof<torch.Tensor>
interface ILayer with
member _.Forward(x: torch.Tensor) =
out <- torch.tanh(x)
out
member _.Parameters = []
member _.Out = out
type Embedding(numEmbbedings: int, embedding_dim: int, generator: torch.Generator) =
let weight = torch.randn(numEmbbedings, embedding_dim, generator = generator)
let mutable out = Unchecked.defaultof<torch.Tensor>
interface ILayer with
member _.Forward(x: torch.Tensor) =
out <- weight[x.long()]
out
member _.Parameters = [ weight ]
member _.Out = out
type FlattenConsecutive(n) =
let mutable out = Unchecked.defaultof<torch.Tensor>
interface ILayer with
member _.Forward(x: torch.Tensor) =
// let e = torch.randn(4, 8, 10)
// torch.concat(System.Collections.Generic.List [
// e[ torch.TensorIndex.Slice(), torch.TensorIndex.Slice(0, 8, 2), torch.TensorIndex.Slice() ]
// e[ torch.TensorIndex.Slice(), torch.TensorIndex.Slice(1, 8, 2), torch.TensorIndex.Slice() ]
// ], dim = 2)
let B = x.shape[0]
let T = x.shape[1]
let C = x.shape[2]
out <- x.view(B, T/n, C*n)
if out.shape[1] = 1 then
out <- out.squeeze(dim = 1)
out
member _.Parameters = []
member _.Out = out
type Sequential(layers: ILayer list) =
member _.Forward(input: torch.Tensor) =
let mutable x = input
for layer in layers do
x <- layer.Forward(x)
x
member _.Parameters = layers |> Seq.map (fun x -> x.Parameters) |> Seq.concat |> Seq.toList
member _.Layers = layers
// Build model
let model = Sequential [
Embedding(size, n_embed, g)
FlattenConsecutive(2); Linear(n_embed * 2, n_hidden, generator = g); BatchNorm1d(n_hidden); Tanh()
FlattenConsecutive(2); Linear(n_hidden * 2, n_hidden, generator = g); BatchNorm1d(n_hidden); Tanh()
FlattenConsecutive(2); Linear(n_hidden * 2, n_hidden, generator = g); BatchNorm1d(n_hidden); Tanh()
Linear(n_hidden, size, generator = g)
]
do use _ = torch.no_grad()
// Make the last Linear layer less confident
(model.Layers |> List.last :?> Linear).UpdateWeight(fun x -> x * scalar(0.1))
// Prepare parameters
let calcLoss (target: torch.Tensor) (input : torch.Tensor) = cross_entropy(input, target.long())
let setIsTraining(isTraining) =
for layer in model.Layers do
match layer with
| :? BatchNorm1d as b -> b.IsTraining <- isTraining
| _ -> ()
model.Parameters |> Seq.iter (fun p -> p.requires_grad <- true)
printfn "Total parameters %d" (model.Parameters |> Seq.sumBy (fun x -> x.NumberOfElements))
// Total parameters 45897
// Used to keep track all the loss on every epoch
let lossi = System.Collections.Generic.List<float32>()
let upgradeToData = System.Collections.Generic.Dictionary<int, System.Collections.Generic.List<float32>>()
let epochs = 100_000
let batchSize = 32
setIsTraining true
// Start the training
for i in 1..epochs do
// mini batch, get a batch of training set for training
let ix = torch.randint(0, int X_train.shape[0], [| batchSize |], generator = g)
let Xb, Yb = X_train[ix], Y_train[ix]
// forward pass
let logits = model.Forward(Xb.float())
let loss = calcLoss Yb logits
for p in model.Parameters do
if p.grad() <> null then p.grad().zero_() |> ignore
loss.backward()
// Calculate learning rates
let learningRate =
if i < 20_000 then 0.1
else 0.01
// update
for i, p in List.indexed model.Parameters do
let newData = p - scalar(learningRate) * p.grad()
p.data<float32>().CopyFrom(newData.data<float32>().ToArray())
lossi.Add(loss.item())
use _ = torch.no_grad()
for i, p in List.indexed model.Parameters do
if upgradeToData.ContainsKey(i) |> not then upgradeToData[i] <- System.Collections.Generic.List<float32>()
upgradeToData[i].Add((scalar(learningRate) * p.grad().std() / p.std()).log10().item())
if i <> 0 && i % 10_000 = 0 then
printfn $"loss = {loss.item<float32>()} \t learning rate = {learningRate}"
// loss = 2.1931758 learning rate = 0.1
// loss = 2.6126218 learning rate = 0.01
// loss = 1.505485 learning rate = 0.01
// loss = 1.6227001 learning rate = 0.01
// loss = 1.564033 learning rate = 0.01
// loss = 2.0126185 learning rate = 0.01
// loss = 1.7080485 learning rate = 0.01
// loss = 1.4627122 learning rate = 0.01
// loss = 1.7411556 learning rate = 0.01
// loss = 1.512068 learning rate = 0.01
let lossiY = torch.tensor(lossi.ToArray()).view(-1, 1000).mean([|1L|]).data<float32>()
Chart.Line([1L..lossiY.Count], lossiY)
|> Chart.withSize(900, 400)
// The final loss
setIsTraining false
model.Forward(X_train) |> calcLoss Y_train
// [], type = Float32, device = cpu, value = 1.5705
// The loss for the dev set
setIsTraining false
model.Forward(X_test) |> calcLoss Y_test
// [], type = Float32, device = cpu, value = 2.3523

let generateNameByNetwork () =
setIsTraining false
let mutable shouldContinue = true
// used to predict the next char, <<< => ?
let mutable context = [| for _ in 1..block_size -> 0L |]
let name = Text.StringBuilder()
while shouldContinue do
let logits = model.Forward(torch.tensor(context ).view(-1, block_size))
let probs = softmax(logits, dim = 1)
// Pick one sample from the row, according to the probobility in row
let ix = torch.multinomial(probs, num_samples = 1, replacement = true, generator = g).item<int64>()
context <- Array.append context[1..] [|ix|]
if int ix = 0 then
shouldContinue <- false
else
ix |> int |> itoc |> name.Append |> ignore
name.ToString()
[1..5] |> Seq.iter (ignore >> generateNameByNetwork >> print)
kayland
ticrys
omolae
tiah
jaysion
[
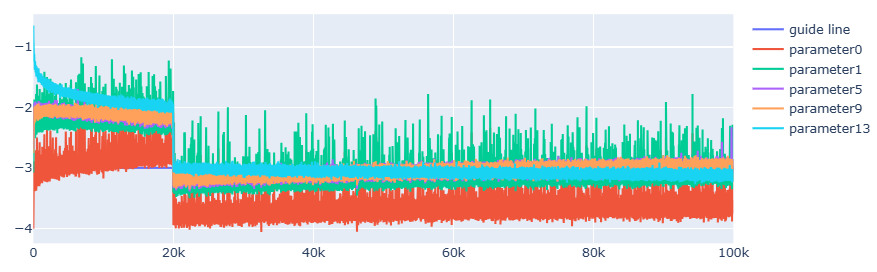
Chart.Line([1..upgradeToData[0].Count], [for _ in 1..upgradeToData[0].Count -> -3], Name = "guide line")
for i, p in List.indexed model.Parameters do
if p.ndim = 2 then
Chart.Line([1..upgradeToData[i].Count], upgradeToData[i], Name = $"parameter{i}")
]
|> Chart.combine
|> Chart.withSize(900, 400)